|
Using Heaps in Embedded Systems
by Ralph Moore
January 18, 2022
I recently read an interesting heap article (Ref. 1) posted on embedded.com. While I largely agree with its author, Colin Walls, I thought it would be interesting to elaborate on some of his points. Heaps are becoming common in embedded systems due to growth in complexity and due to bringing in third-party software that was not necessarily designed for embedded systems. Such software is likely to require heaps. IoT is a major driver of these changes. So, I think the question is no longer whether to use heaps in embedded systems, but rather how to use them.
Colin lists three problems with heaps:
- Non-reentrancy.
- Non-deterministic.
- Allocation failure.
Non-Reentrancy
He suggests either isolating all memory allocations to a single task or having a memory allocation server task. In the first case, it is adequate if all tasks using the heap have the same priority. But this may not be practical if there is third party software using heaps in the system as well as the system, itself. The second, while nice-sounding, imposes two task switching overheads on every heap operation. If there is code that is allocating and freeing blocks frequently, this could hurt system performance.
A better alternative is to use a mutex. Even in a very dynamic-memory, non-C++ system, heap malloc()'s and free()'s cannot dominate because useful work must be done. Therefore, probably 95-99% of the time, the heap mutex will be free, when tested. If a mutex is free, MutexGet() is usually fast — especially when compared to a heap operation that follows it. Thus the overhead on the majority of heap operations occurring during runtime should be small to negligible. If, however, the heap mutex is not free, assuming a timeout has been specified, the mutex overhead is greater and two task switches are required. But, this may happen only 1-5% of the time.
Another advantage of using a heap mutex, is its timeout. This allows the program to wait a reasonable time to get or to free a block, rather than failing immediately or waiting forever. Of course, waiting on a server task might also offer a timeout, depending upon the RTOS. So this advantage may be a push, but testing a mutex to get a resource seems more intuitive.
Non-Deterministic
It is certainly true, as stated in Ref 1, that all tasks need not necessarily be deterministic. However, these must be low-priority tasks, else they may block tasks that do have deadlines. This could cause a problem if a relatively important task, occasionally needed to do a heap operation — what priority should it have? Also, a low-priority task that requires a heap operation may need to increase its urgency as its deadline nears. Of course, most RTOSs allow task priorities to be changed, but doing so creates complex scenarios for operation and for debugging. Generally, the type of heap envisioned in the foregoing is a serial heap, which must search from chunk[1] to chunk until it finds a big enough one. This can take a very long time if the heap is big. However, there is a better alternative — a bin heap.
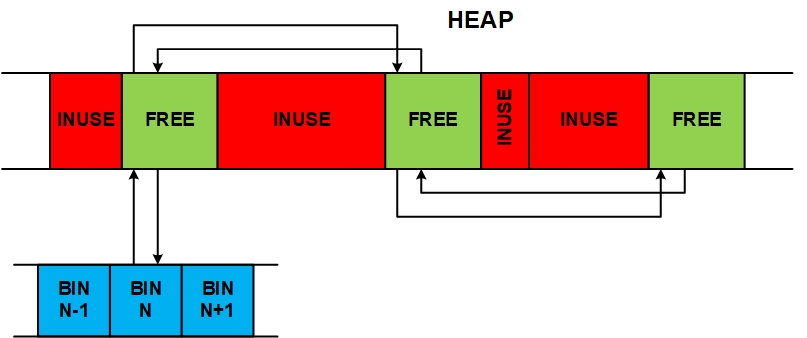
dlmalloc() (Ref 2.) is the first bin heap that I know of, which became popular, although others probably preceded it. dlmalloc has a small bin array (SBA) for small blocks and bin trees for larger blocks. Each SBA bin has a single chunk size and the bins are organized in successive sizes such as 16, 24, 32, etc. The requested block size is used to form an index into the SBA and the first chunk in the selected bin is taken. This is almost as fast as a block pool. A newer approach is to replace bin trees with large bins. Each large bin holds a range of chunk sizes from one to many. So the first large bin might cover 128 to 248 bytes, the next from 256 to 504, and eventually, the last would cover up to the maximum chunk size (e.g. 4096). Large bins have the effect of dividing the heap, excluding the SBA chunks, into several mini heaps. A fast search algorithm allows finding the correct large bin, based upon the requested block size.
Two interesting aspects of large bins in embedded systems are that: (1) Embedded systems always have spare idle time to allow for peak loads. During these idle times, large bins can be sorted so that, when searching from the start of a large bin, the first big-enough chunk found is also the best fit chunk in the bin. Since a large bin is sorted, certain fast search algorithms can be applied for finding chunks in it. (2) Small bins (i.e. having a single chunk size) can be interspersed among the large bins. Thus, a frequently requested size (e.g. protocol block size) can be allocated rapidly.
Colin suggests using multiple block pools such as 16, 32, 64, and 128 byte block sizes as an alternative to a heap. This method has been used in embedded systems from the very beginning and works well for simple embedded systems. There are some problems with it, however: (1) Each block pool must have enough blocks to meet peak demand for its block size, and (2) Many allocated blocks may be much smaller than the pool blocks they are in — e.g. slightly more than half. With regard to (1), peak demand for every size is highly unlikely to occur at the same time, yet block pools have no flexibility to adjust to this. With regard to (2), creating more block pools with intermediate sizes would help, but this exacerbates problem (1). As embedded systems become more complex, these problems can result in poor memory efficiencies. Heaps are much more adaptable to changing block size and number requirements and thus are the solution preferred by most programmers.
Allocation Failure
Allocation failure is the big bogeyman for heaps — bad for attended systems, potentially disastrous for unattended, embedded systems. Interestingly, dlmalloc() always merges freed chunks. This strikes me as curious because it undermines the value of bins. If, for example, a chunk is freed that is adjacent, in the heap, to a free chunk in a bin, the two will be merged and put into a larger bin. But the free chunk in the bin was probably there because it is needed by the system. Thus when the system needs that chunk size, its bin may be empty and the heap must get a larger chunk, split it, put the remnant into a smaller bin and return the requested block in the chunk. So several unnecessary operations occur: Free: get chunk from bin, merge chunks, put merged chunk into another bin; Malloc: split chunk, put remnant into a bin. This hardly seems to be an efficient plan!
Of course bins could be packed with free chunks separated by tiny allocated chunks. Then the bin chunks could never be merged. However, this seems to be inefficient and it does not allow for varying chunk size requirements, during operation — a similar problem to block pools.
I think a better solution is to implement dynamic merge control. Then, merge is off until the heap is showing signs of excessive fragmentation, then merge is turned on until those signs abate. Ref 2 states that there is no perfect solution to merge control and hence, this may be a bad idea. However, in my experience, embedded systems tend to fall into what might be called rhythms. They are not as random as might be supposed. Hence, for a given embedded system a dynamic merge algorithm might work just fine — especially for small partition heaps that see little action. If not, merge can just be turned off permanently.
Should an allocation fail to occur due to fragmentation, a safety feature is to implement a recovery function, which, upon allocation failure, immediately goes into operation. It works by tracing through the heap, chunk by chunk, until it finds adjacent free chunks that can be merged to satisfy the allocation request. It then merges the chunks and returns to malloc(), which finds the merged chunk and returns the requested block from it. So a hiccup occurs, but not an operation failure, unless the recovery function, itself, fails. In that case, a system reboot may be necessary, or possibly a less important task can be induced to give up its blocks — e.g. by deleting it.
Conclusion
As embedded system complexity continues to increase, it is becoming necessary to incorporate heaps into embedded systems. This, in turn, requires new kinds of heaps, which meet the needs of modern embedded systems. Refs. 4, 5, and 6 discuss different aspects of a heap designed to meet this need.
References
- Colin Walls, Use malloc()? Why Not?, embedded.com, February 2021.
- Doug Lea, A Memory Allocator, December 1996.
- Wilson, Paul R, Dynamic Storage Allocation: A Survey and Critical Review, University of Texas at Austin, Sept 1995.
- Ralph Moore, eheap™ Part 1: Configuration, Micro Digital, August 2021
.
- Ralph Moore, eheap™ Part 2: Enhanced Debugging, Micro Digital, August 2021.
- Ralph Moore, eheap™ Part 3: Self-Healing, Micro Digital, August 2021.
Ralph Moore is a graduate of Caltech. He and a partner started Micro Digital Inc. in 1975 as one of the first microprocessor design services. Now Ralph is primarily the Company RTOS innovator. He does all functions including product definition, architecture, design, coding, debugging, documenting, and assisting customers. Ralph's current focus is to improve the security of IoT and embedded devices through firmware partitioning. He believes that it is the most practical approach to achieving acceptable security for devices connected to networks and to the Cloud.
Copyright © 2022 Micro Digital, Inc. All rights reserved.
|